Fooling Clarifai's content moderation model
In this post, we describe the Content Moderation model hosted by Clarifai which we attack using our query-based black-box attack. We mainly experiment with a 256x256 pixel RGB image of various kinds of opioids, which is meant to be flagged by the content moderation API as an image of drugs.

When the API returns the classification outcome for this image, it returns the following dictionary:
{u'outputs': [{u'created_at': u'2017-09-14T23:05:00.048935594Z',
u'data': {u'concepts': [{u'app_id': u'main',
u'id': u'ai_8QQwMjQR',
u'name': u'drug',
u'value': 0.99996763},
{u'app_id': u'main',
u'id': u'ai_V76bvrtj',
u'name': u'explicit',
u'value': 2.3027327e-05},
{u'app_id': u'main',
u'id': u'ai_kBBGf7r8',
u'name': u'gore',
u'value': 1.756333e-05},
{u'app_id': u'main',
u'id': u'ai_RtXh5qkR',
u'name': u'suggestive',
u'value': 1.3455325e-05},
{u'app_id': u'main',
u'id': u'ai_QD1zClSd',
u'name': u'safe',
u'value': 7.980809e-06}]},
u'id': u'dc69ebb54fd942488ffa4dd488d16e8b',
u'input': {u'data': {u'image': {u'base64': u'true',
u'url': u'https://s3.amazonaws.com/clarifai-api/img2/prod/small/c0b5b6be99074a458dd6f7062f2452b8/a2805bdf4f8f4e70a8d699969488623a'}},
u'id': u'ddbf3fa9cc414f12988aba5827cc53fb'},
u'model': {u'app_id': u'main',
u'created_at': u'2017-05-16T19:20:38.733764Z',
u'display_name': u'Moderation',
u'id': u'd16f390eb32cad478c7ae150069bd2c6',
u'model_version': {u'created_at': u'2017-05-16T19:20:38.733764Z',
u'id': u'b42ac907ac93483484483a0040a386be',
u'status': {u'code': 21100,
u'description': u'Model trained successfully'}},
u'name': u'moderation',
u'output_info': {u'message': u'Show output_info with: GET /models/{model_id}/output_info',
u'type': u'concept',
u'type_ext': u'concept'}},
u'status': {u'code': 10000, u'description': u'Ok'}}],
u'status': {u'code': 10000, u'description': u'Ok'}}
On this image, the classifier’s confidence that the image belongs to the concept class ‘drugs’ is 0.99, which is given in the ‘concepts’ output. The classifier’s confidence that the image is ‘safe’ is negligible.
Since the black-box Content Moderation model returns the confidence scores, the Gradient Estimation attack can be used. Without query reduction, even a single step attack would take roughly 200,000 queries. In order to reduce the number of queries, the random grouping method for query reduction is used with a group size of 1,000. This leads to a total of 197 queries to the model through the API. Using a perturbation magnitude of 32 (maximum possible is 255) with a single step in the direction of the estimated gradient, the following adversarial image is obtained:
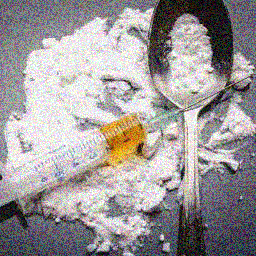
This image is classified as ‘safe’ with a confidence of 0.96 by the content moderation model. However, the content that was to be moderated, i.e. the presence of drugs in the image, is still clearly visible in the image. This represents a serious concern as malicious entities can use techniques similar to the one described here to ensure that offensive content isn’t flagged.